GPT4又升级了GPT4-Turbo,这个最厉害的地方在于,它支持多模态,也就是支持图片、音频、视频作为输入了。
Sider里也有了这个功能,我试了一下,感觉可用,但不能期望太高,对于电脑上的截图,比如一个表格的截图,完全清晰的情况下,还是比较好用的,对于其它的拍照、风景人物物体等等的照片,它可以理解个大概。下面是我自己尝试的一些例子:
(需要注意的是,发一个图片,问答一次后,如果想继续就此图片聊,你必须再次点击引用这个图片,仅仅提及它刚才的回答,它是不记得之前的图片的,而你再次引用图片时,它又不一定记得它自己刚才回答了什么,所以,基本上约等于只能就图片进行一次性对话,当然,你可以不断修改自己的提问、加一些背景描述以使得它回答的更准确一些,另外它好像会拒绝回答关于图片里的地理位置或可能泄露隐私的信息,不知道是不是我的提问的prompt不对)

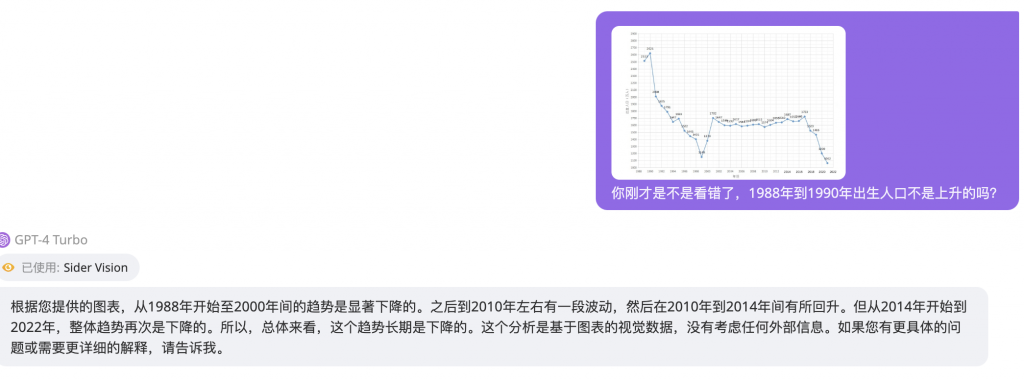
上面这个例子,我是给了一张出生率的曲线图给它,让他描述一下,由于纵坐标上的中文是转了90度写的,所以它看不懂,所以我给图的同时告诉它纵轴是出生人口数量,横轴是年份;第一次它说的基本没错,而且猜测到这是中国的人口出生率曲线,但是它把最开始的1988年到1990年说成有所下降,我纠正它,它还不服气。。。。还说是“显著下降”。。。。


这是一个英语的作文题,这个照片其实不算清楚,有点歪,但它还是理解了,唯一的错误是没看懂“交通时长”几个字指的是什么,我纠正了后,它接受了。但最后还是画蛇添足了一下,我不知道它听谁说的图书馆舒适通风宽敞明亮,自习室就是舒适安静。。。。真是令人崩溃。不过写的作文还是相当高质量的。

最后这个是让他对我们同学聚会拍的一张照做个描述,整体讲的相当不错,但为什么最简单的数人头都会数错啊?!!这明明是9个人,偏要说是8个!!不知道它是看谁不顺眼。。。。唉。。。
总之,AI的能力还是相当厉害的了,对于这些错误,不能用人类的方式来理解,它学习的方式和我们从小孩到大人的成长是不一样的。也许再过5年,AI能够再上一个大的台阶。


文章评论